[PYTHON] EDA de la prime d'assurance médicale et problème de retour
Aperçu
Comme il existe une opportunité de former le personnel qui n'a pas de connaissances en apprentissage automatique dans l'entreprise, nous avons décidé de créer du matériel pédagogique pour les problèmes d'EDA, de clustering et de régression en utilisant les données de primes d'assurance médicale américaines. L'ensemble de données utilise [this] de Kaggle (https://www.kaggle.com/mirichoi0218/insurance) La sensation que j'ai faite à peu près peut sembler un peu difficile, je ne vais donc pas l'utiliser pour du matériel pédagogique Préparons-en un plus simple séparément
- Période de mise en œuvre: novembre 2020 --Environnement: Google Colaboratory
base de données
La structure de Insurance.csv est illustrée dans la figure ci-dessous. Les frais indiquant les primes d'assurance médicale seront prédits par ce retour
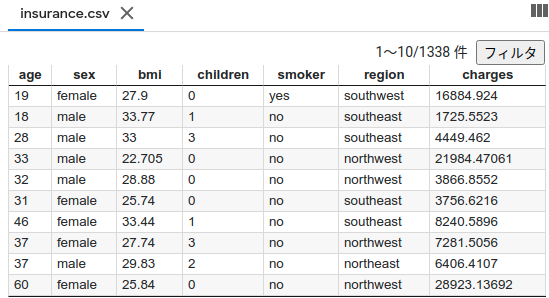
Publiez la description de chaque colonne Columns age: age of primary beneficiary sex: insurance contractor gender, female, male bmi: Body mass index, providing an understanding of body, weights that are relatively high or low relative to height, objective index of body weight (kg / m ^ 2) using the ratio of height to weight, ideally 18.5 to 24.9 children: Number of children covered by health insurance / Number of dependents smoker: Smoking region: the beneficiary's residential area in the US, northeast, southeast, southwest, northwest. charges: Individual medical costs billed by health insurance
EDA(Explanatory Data Analysis) Certains mots peuvent ne pas vous être familiers Le processus consistant à confirmer d'abord la structure de l'ensemble de données à analyser et à établir une stratégie pour l'analyser (je pense) Nécessite le type d'outil, la familiarité et l'intuition La méthode d'analyse est différente pour chaque personne, veuillez donc garder ce qui suit pour référence seulement.
Tout d'abord, ouvrez le fichier et vérifiez le contenu et les données pour les éléments manquants.
import numpy as np
import pandas as pd
import os
from sklearn.preprocessing import LabelEncoder
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv('insurance.csv')
#Affichage de l'ensemble de données
print(df.tail())
#Vérifier NaN
df.isnull().sum()
 Vous pouvez voir qu'il n'y a pas de défauts (heureusement car c'est un peu gênant s'il y en a)
Puisqu'il contient des données catégorielles, numérisez-les avec LabelEncoder
Vous pouvez voir qu'il n'y a pas de défauts (heureusement car c'est un peu gênant s'il y en a)
Puisqu'il contient des données catégorielles, numérisez-les avec LabelEncoder
#Codage des données de catégorie
# sex
le = LabelEncoder()
le.fit(df.sex.drop_duplicates())
df.sex = le.transform(df.sex)
# smoker or not
le.fit(df.smoker.drop_duplicates())
df.smoker = le.transform(df.smoker)
# region
le.fit(df.region.drop_duplicates())
df.region = le.transform(df.region)
#Affichage de l'ensemble de données
print(df.tail())
 Remplacé par un entier
Regardez le coefficient de corrélation global et frappez les variables explicatives qui affectent les frais
Remplacé par un entier
Regardez le coefficient de corrélation global et frappez les variables explicatives qui affectent les frais
print(df.corr())
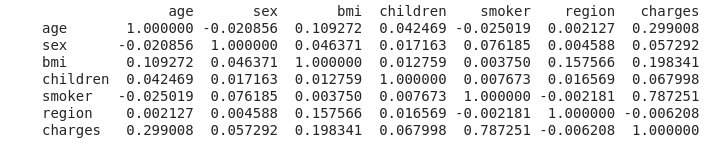 Le fumeur montre une très forte corrélation à 0,787251
Vient ensuite l'âge de 0,299008, et je crains que le coefficient de corrélation de bmi (= poids / taille ^ 2), qui indique le degré d'obésité, soit plus petit que prévu.
Cependant, c'est un calcul ponctuel avec juste ".corr ()", donc je suis content d'avoir utilisé Python.
Le fumeur montre une très forte corrélation à 0,787251
Vient ensuite l'âge de 0,299008, et je crains que le coefficient de corrélation de bmi (= poids / taille ^ 2), qui indique le degré d'obésité, soit plus petit que prévu.
Cependant, c'est un calcul ponctuel avec juste ".corr ()", donc je suis content d'avoir utilisé Python.
Afficher toute la distribution
sns.pairplot(df.loc[:, ['age', 'sex', 'bmi', 'children', 'smoker', 'region', 'charges']], height=2);
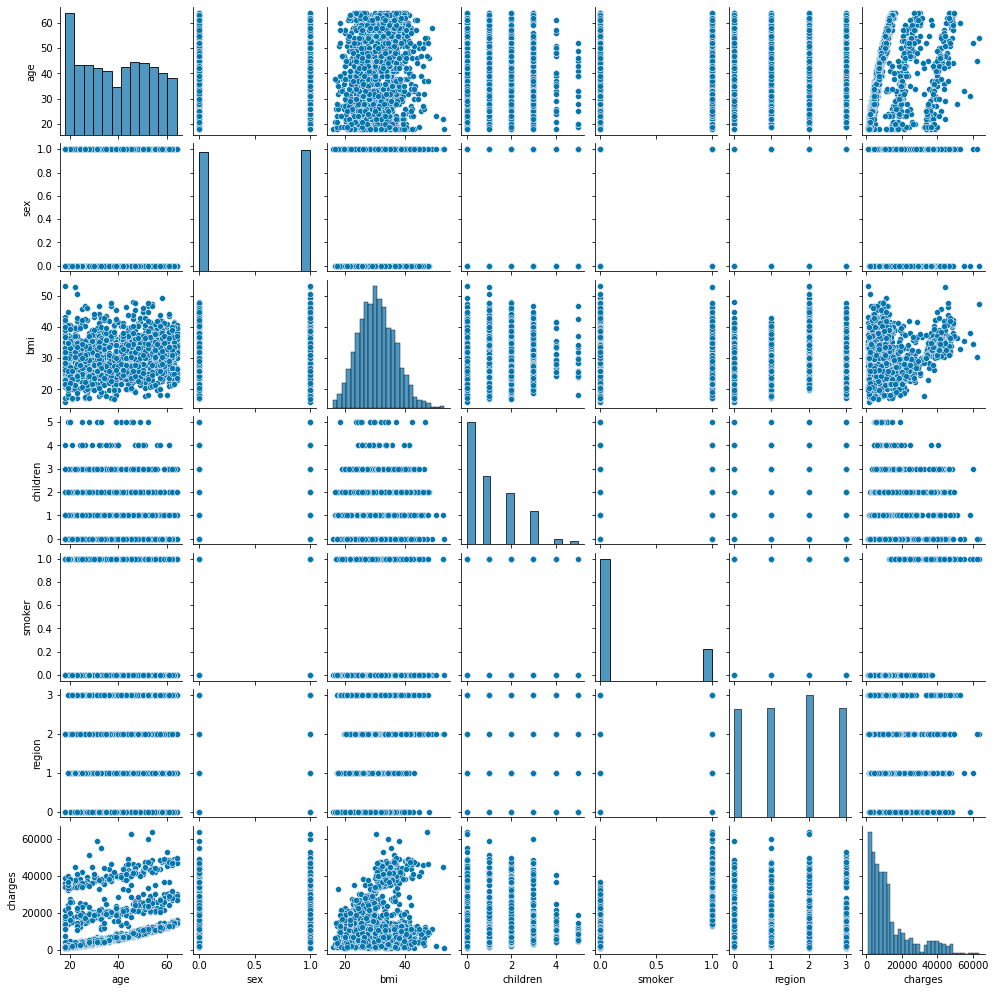 La distribution caractéristique est indiquée ci-dessous, alors concentrez-vous sur l'âge, l'IMC, le fumeur.
Il semble qu'il puisse être divisé en 3 groupes, mais analysez ce qui l'a amené à être divisé en 3 groupes
La distribution caractéristique est indiquée ci-dessous, alors concentrez-vous sur l'âge, l'IMC, le fumeur.
Il semble qu'il puisse être divisé en 3 groupes, mais analysez ce qui l'a amené à être divisé en 3 groupes
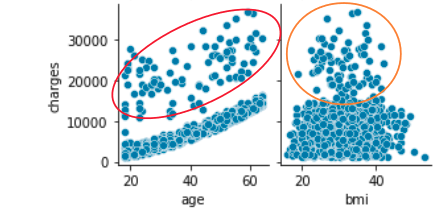
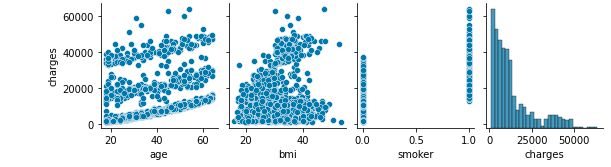 La répartition des charges d'âge est très caractéristique
Cherchons le fumeur qui était fortement corrélé
La répartition des charges d'âge est très caractéristique
Cherchons le fumeur qui était fortement corrélé
# smoker-Jetons un coup d'œil aux frais
sns.boxplot(x="smoker", y="charges", data=df)
#Confirmer par numéro
df_s0 = df[df['smoker'] == 0] #Non fumeur
df_s1 = df[df['smoker'] == 1] #fumeur
pd.set_option('display.max_rows', 20)
pd.set_option('display.max_columns', None)
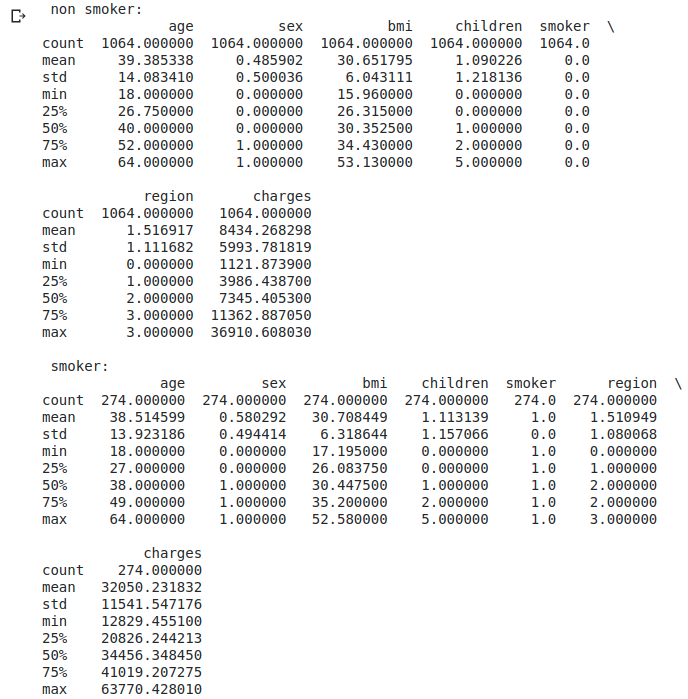
print(' non smoker:\n' + str(df_s0.describe()))
print('\n smoker:\n' + str(df_s1.describe()))
print('\n Primes d'assurance médicale pour les non-fumeurs' + str(df_s1['charges'].mean() / df_s0['charges'].mean()) + 'Cela prend deux fois plus.')
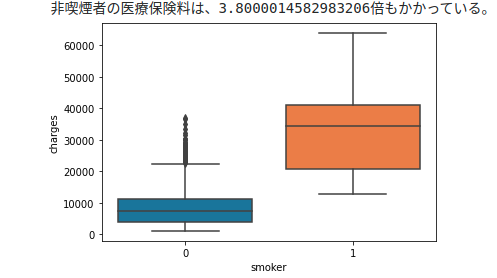
Le diagramme des moustaches en forme de boîte montre que les non-fumeurs correspondent aux pics élevés à gauche de l'histogramme des charges.
À l'inverse, l'orange du fumeur peut être considérée comme une collection de deux montagnes avec un histogramme de faibles charges.
Vérifier la distribution uniquement pour les non-fumeurs
sns.pairplot(df_s0.loc[:, ['age', 'bmi', 'charges']], height=2);
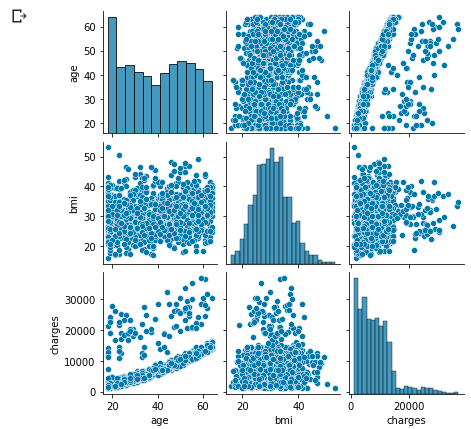 La répartition des charges d'âge susmentionnée pourrait être séparée
Cette distribution caractéristique semble avoir été influencée par le fait de fumer ou non
La répartition des charges d'âge susmentionnée pourrait être séparée
Cette distribution caractéristique semble avoir été influencée par le fait de fumer ou non
 Même les non-fumeurs vont à l'hôpital à un rythme constant quel que soit leur âge, alors est-ce que la dispersion supérieure de la distribution des charges selon l'âge représente cela?
Cette dispersion et la dispersion de la distribution des charges bmi semblent être liées, alors essayez de regrouper.
Même les non-fumeurs vont à l'hôpital à un rythme constant quel que soit leur âge, alors est-ce que la dispersion supérieure de la distribution des charges selon l'âge représente cela?
Cette dispersion et la dispersion de la distribution des charges bmi semblent être liées, alors essayez de regrouper.
from sklearn.cluster import KMeans
#from sklearn.cluster import MiniBatchKMeans
df_wk = df_s0.drop(['sex', 'children', 'smoker', 'region'], axis=1)
kmeans_model = KMeans(n_clusters=2, random_state=1, init='k-means++', n_init=10, max_iter=300, tol=0.0001, algorithm='auto', verbose=0).fit(df_wk)
#kmeans_model = MiniBatchKMeans(n_clusters=2, random_state=0, max_iter=300, batch_size=100, verbose=0).fit(df_wk)
df_wk['cluster'] = kmeans_model.labels_
labels = kmeans_model.labels_
print(labels.sum())
color_codes = {0:'r', 1:'g', 2:'b'}
colors = [color_codes[x] for x in labels]
ax1 = df_wk.plot.scatter(x='age', y='charges', c=colors)
ax1 = df_wk.plot.scatter(x='bmi', y='charges', c=colors)
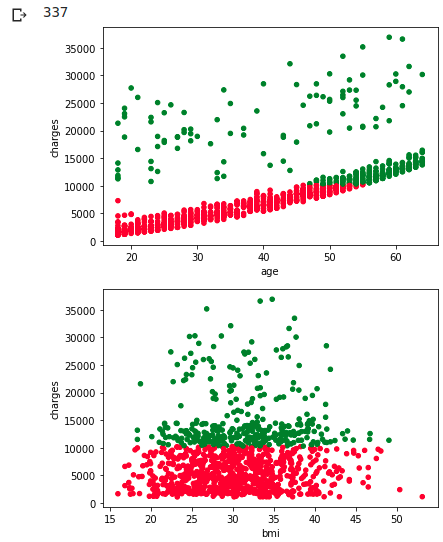 C'est dommage que nous n'ayons pas pu les séparer proprement, mais on peut dire que les deux cartes de répartition mentionnées ci-dessus se correspondent.
Cependant, je ne comprends pas la raison pour laquelle les frais sont élevés à tous les âges, quelle que soit la taille de l'IMC.
Je n'ai pas encore enquêté sur les enfants et la région, et il semble que les enfants soient plus liés à la variation du BMI.
Si vous regardez la répartition des non-fumeurs par enfants (= nombre de personnes à charge), vous pouvez voir la relation entre la composition de la famille et le bmi.
C'est dommage que nous n'ayons pas pu les séparer proprement, mais on peut dire que les deux cartes de répartition mentionnées ci-dessus se correspondent.
Cependant, je ne comprends pas la raison pour laquelle les frais sont élevés à tous les âges, quelle que soit la taille de l'IMC.
Je n'ai pas encore enquêté sur les enfants et la région, et il semble que les enfants soient plus liés à la variation du BMI.
Si vous regardez la répartition des non-fumeurs par enfants (= nombre de personnes à charge), vous pouvez voir la relation entre la composition de la famille et le bmi.
df_c0 = df_s0[df_s0['children'] == 0] # children = 0
df_c1 = df_s0[df_s0['children'] == 1] # children = 1
df_c2 = df_s0[df_s0['children'] == 2] # children = 2
df_c3 = df_s0[df_s0['children'] == 3] # children = 3
df_c4 = df_s0[df_s0['children'] == 4] # children = 4
df_c5 = df_s0[df_s0['children'] == 5] # children = 5
plt.figure(figsize=(12, 6))
plt.hist([df_c0['charges'], df_c1['charges'], df_c2['charges'], df_c3['charges'], df_c4['charges'], df_c5['charges']]
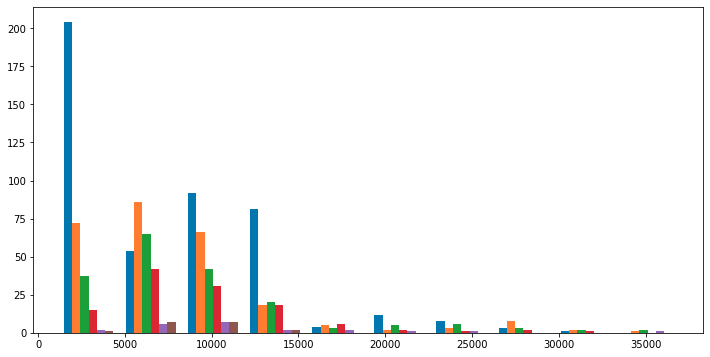
En regardant l'histogramme des frais> 15000, nous ne pouvons voir aucune fonctionnalité dans les frais et le nombre d'enfants Après tout, est-ce simplement «parce que même les non-fumeurs vont à l'hôpital à un certain rythme quel que soit leur âge»? Teste si bmi est normalement distribué à des charges> 15000
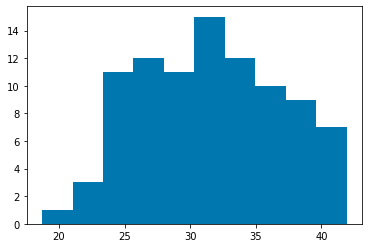
df_b0 = df_s0[df_s0['charges'] > 15000] # children = 0
plt.hist([df_b0['bmi']])
import scipy.stats as stats
stats.probplot(df_b0['bmi'], dist="norm", plot=plt)
stats.shapiro(df_b0['bmi'])
(0.9842953681945801, 0.3445127308368683)
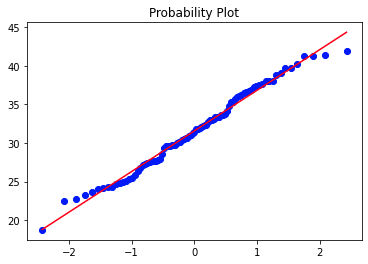 Ni l'histogramme, ni le diagramme QQ ni le test de Shapiro-Wilke (valeur p = 0,3445) ne montrent que l'on ne peut pas dire que la distribution est normale.
Après tout, je n'ai pas vraiment compris la cause
Eh bien, laissons cela comme une distribution naturelle à cause de la distribution normale ...
Ni l'histogramme, ni le diagramme QQ ni le test de Shapiro-Wilke (valeur p = 0,3445) ne montrent que l'on ne peut pas dire que la distribution est normale.
Après tout, je n'ai pas vraiment compris la cause
Eh bien, laissons cela comme une distribution naturelle à cause de la distribution normale ...
Cette fois, vérifiez la distribution uniquement par les fumeurs
sns.pairplot(df_s1.loc[:, ['age', 'bmi', 'charges']], height=2);
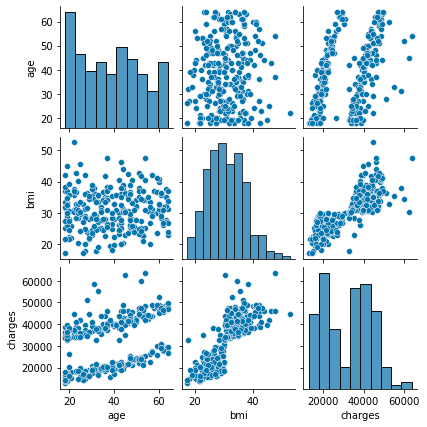 Intuitivement, il semble que l'âge et l'IMC correspondent comme le montre la figure ci-dessous.
Intuitivement, il semble que l'âge et l'IMC correspondent comme le montre la figure ci-dessous.
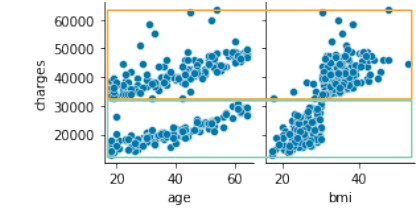 Essayez de regrouper comme vous le feriez pour un non-fumeur
Essayez de regrouper comme vous le feriez pour un non-fumeur
df_wk = df_s1.drop(['sex', 'children', 'smoker', 'region'], axis=1)
kmeans_model = KMeans(n_clusters=2, random_state=1, init='k-means++', n_init=10, max_iter=300, tol=0.0001, algorithm='auto', verbose=0).fit(df_wk)
df_wk['cluster'] = kmeans_model.labels_
labels = kmeans_model.labels_
print(labels.sum())
color_codes = {0:'r', 1:'g', 2:'b'}
colors = [color_codes[x] for x in labels]
ax1 = df_wk.plot.scatter(x='age', y='charges', c=colors)
ax1 = df_wk.plot.scatter(x='bmi', y='charges', c=colors)
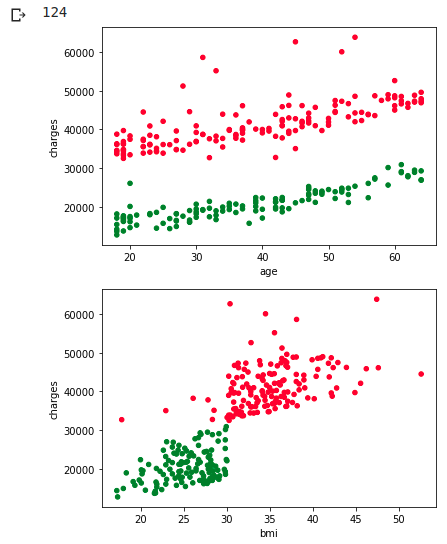 Comme je m'y attendais, cette fois j'ai pu le séparer proprement
Comme je m'y attendais, cette fois j'ai pu le séparer proprement
Conclusion de l'EDA
Les personnes ayant un IMC élevé ont des primes d'assurance médicale élevées indépendamment de leurs habitudes de fumer, mais l'âge n'a pas d'importance (ça me fait mal aux oreilles ...) À partir des données du fumeur, il a été constaté que la prime d'assurance médicale augmentera encore après bmi = 30. Étant donné que cette limite est trop claire, il peut y avoir des restrictions administratives telles que l'ajout forcé d'éléments d'inspection coûteux lorsqu'elle dépasse 30, par exemple.
sns.regplot(x="bmi", y="charges", data=df_wk)
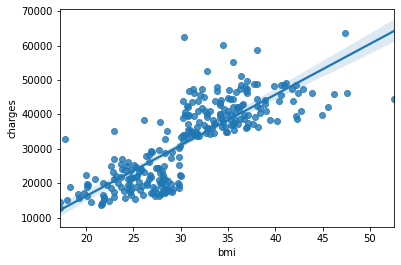 En d'autres termes, par exemple, on peut voir à partir de cet EDA que la ligne de régression indiquée ci-dessus ne doit pas être tracée.
En d'autres termes, par exemple, on peut voir à partir de cet EDA que la ligne de régression indiquée ci-dessus ne doit pas être tracée.
Régression simple, problème de régression multiple
Pour les non-fumeurs, essayez de prédire les charges comme un problème de régression Plus précisément, RMSE évalue la différence de précision de la prévision des charges entre la régression simple (âge uniquement) et la régression multiple (âge, bmi). Nous n'utiliserons pas les résultats du clustering, nous laisserons donc les variations incluses.
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import mean_squared_error
from sklearn import metrics
from sklearn import linear_model
cv_alphas = [0.01, 0.1, 1, 10, 100] #Α pour la vérification croisée
df_wk = df_s0.drop(['sex', 'children', 'smoker', 'region'], axis=1)
#Évaluation et représentation graphique des résultats de Predict
def regression_prid(clf_wk, df_wk, intSample=20, way='single'):
arr_wk = df_wk.values[:intSample]
arr_age, arr_agebmi, arr_charges = arr_wk[:,0], arr_wk[:,0:2], arr_wk[:,2]
if way == 'single':
arr_prid = clf_wk.predict(arr_age.reshape([intSample,1]))
titel1='simple regression'
titel2='RMSE(single) =\t'
else:
arr_prid = clf_wk.predict(arr_agebmi.reshape([intSample,2]))
titel1='multiple regression'
titel2='RMSE(multi) =\t'
rmse = np.sqrt(mean_squared_error(arr_charges, arr_prid))
print(titel2 + str(rmse))
#terrain
arr_chart = df_wk.values[:intSample].reshape([intSample,3])
arr_chart = np.hstack([arr_chart, arr_prid.reshape([intSample,1])])
fig = plt.figure(figsize=(8, 5))
ax = fig.add_subplot(1,1,1)
ax.scatter(arr_chart[:,0],arr_chart[:,2], c='red')
ax.scatter(arr_chart[:,0],arr_chart[:,3], c='blue')
ax.set_title(titel1)
ax.set_xlabel('age')
ax.set_ylabel('charges')
fig.show()
Régression simple par la méthode des moindres carrés
clf = linear_model.LinearRegression()
#Problème de régression simple
clf.fit(df_wk[['age']], df_wk['charges'])
regression_prid(clf, df_wk, 50, 'single')
#Problème de régression multiple
clf.fit(df_wk[['age', 'bmi']], df_wk['charges'])
regression_prid(clf, df_wk, 50, 'multi')
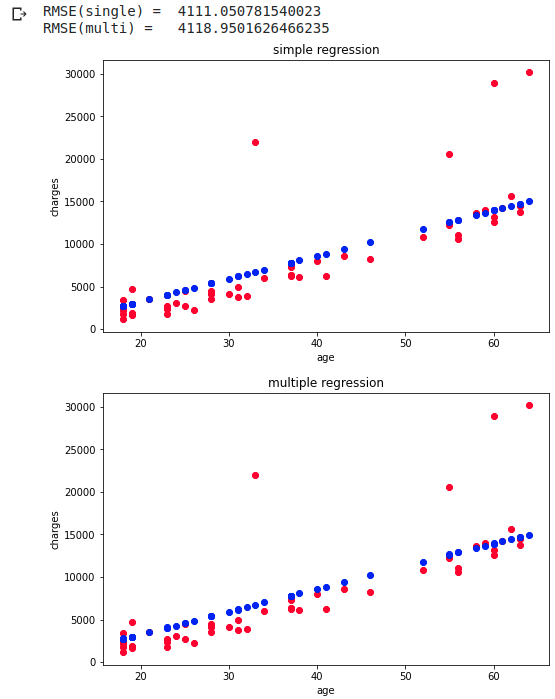
Le haut est une régression simple prédite par l'âge et le bas est une régression multiple prédite par l'âge et l'IMC. RMSE est lorsque prédit avec 20 points, et la régression simple est légèrement plus précise Puisque les données originales sont presque linéaires, la prédiction est directe dans les régressions simples et multiples.
Retour par régularisation L2
Ridge RidgeCV À propos, CV signifie Closs Validation et validation croisée. Veuillez google pour plus de détails sur la vérification croisée
cv_flag = True # True:Vérification croisée
if cv_flag:
clf = linear_model.RidgeCV(alphas=cv_alphas ,cv=3, normalize=False)
#Problème de régression simple
clf.fit(df_wk[['age']], df_wk['charges'])
print("alpha =\t", clf.alpha_)
regression_prid(clf, df_wk, 50, 'single')
#Problème de régression multiple
clf.fit(df_wk[['age', 'bmi']], df_wk['charges'])
print("alpha =\t", clf.alpha_)
regression_prid(clf, df_wk, 50, 'multi')
else:
clf = linear_model.Ridge(alpha=1.0)
#Problème de régression simple
clf.fit(df_wk[['age']], df_wk['charges'])
regression_prid(clf, df_wk, 50, 'single')
#Problème de régression multiple
clf.fit(df_wk[['age', 'bmi']], df_wk['charges'])
regression_prid(clf, df_wk, 50, 'multi')
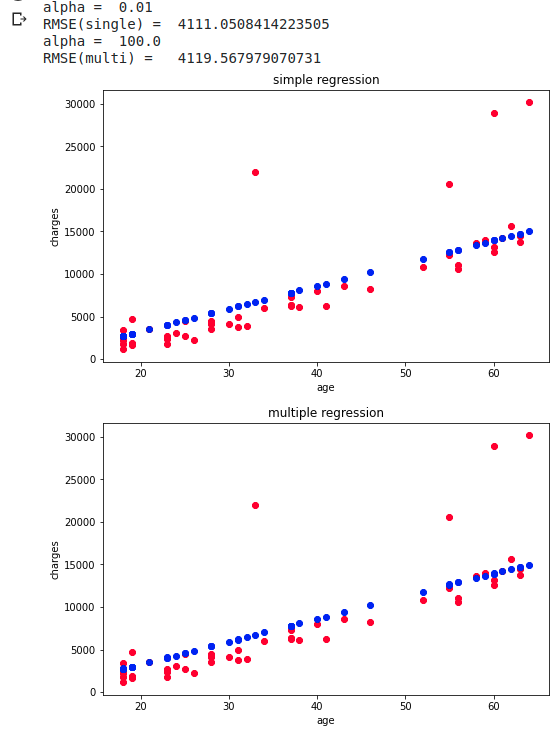
J'ai essayé de prédire en utilisant la vérification des intersections, mais après tout, la régression multiple n'est pas meilleure
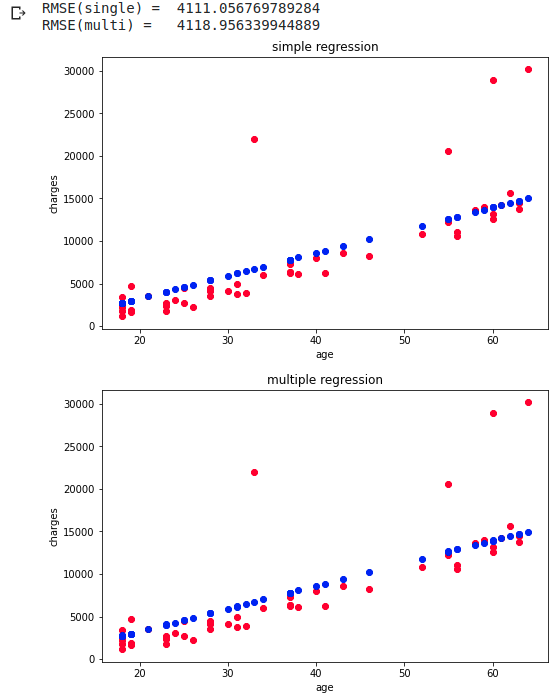
RMSE ne change pas grand-chose sans vérification croisée Après tout, comme les charges augmentent linéairement, je pense que la différence de précision due à la méthode de régression est devenue difficile à faire ressortir.
Retour par régularisation L1
Lasso LassoCV Omis car il remplace uniquement Ridge dans le code ci-dessus par Lasso RMSE était presque inchangé
Recommended Posts