[PYTHON] Save pandas data in Excel format to data assets with Cloud Pak for Data (Watson Studio)
How to save the file to the data asset of the analysis project using project_lib [Another article](https://qiita.com/ttsuzuku/items/eac3e4bedc020da93bc1#%E3%83%87%E3%83%BC%E3% 82% BF% E8% B3% 87% E7% 94% A3% E3% 81% B8% E3% 81% AE% E3% 83% 87% E3% 83% BC% E3% 82% BF% E3% 81% AE% E4% BF% 9D% E5% AD% 98-% E5% 88% 86% E6% 9E% 90% E3% 83% 97% E3% 83% AD% E3% 82% B8% E3% 82% A7 I wrote it in% E3% 82% AF% E3% 83% 88), but it took some tricks to save it in Excel format. After a lot of research, stackoverflow's this article It was valid.
Here is an example that I actually tried.
Pandas dataframe used
#Sample data Iris
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['iris_type'] = iris.target_names[iris.target]
df.head()
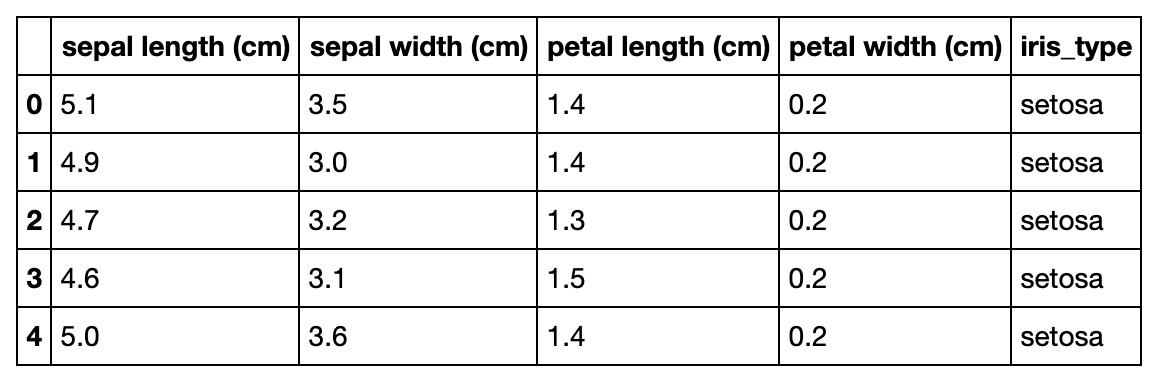
Let's save this data in Excel format. The flow is once saved as an Excel file in the environment with pandas.to_excel,
#Output to the environment once as an Excel file
filename = 'iris.xlsx'
df.to_excel(filename, index=False)
!pwd
!ls -l
# -output-
# /home/wsuser/work
# total 12
# -rw-r-----. 1 wsuser watsonstudio 8737 May 28 06:53 iris.xlsx
Read it as an io byte stream and save it in your analysis project with project_lib.
from project_lib import Project
project = Project.access()
import io
with open(filename, 'rb') as z:
data = io.BytesIO(z.read())
project.save_data(filename, data, set_project_asset=True, overwrite=True)
Make sure it was saved in your analysis project.

Just in case, I will download it and take a look at the contents.
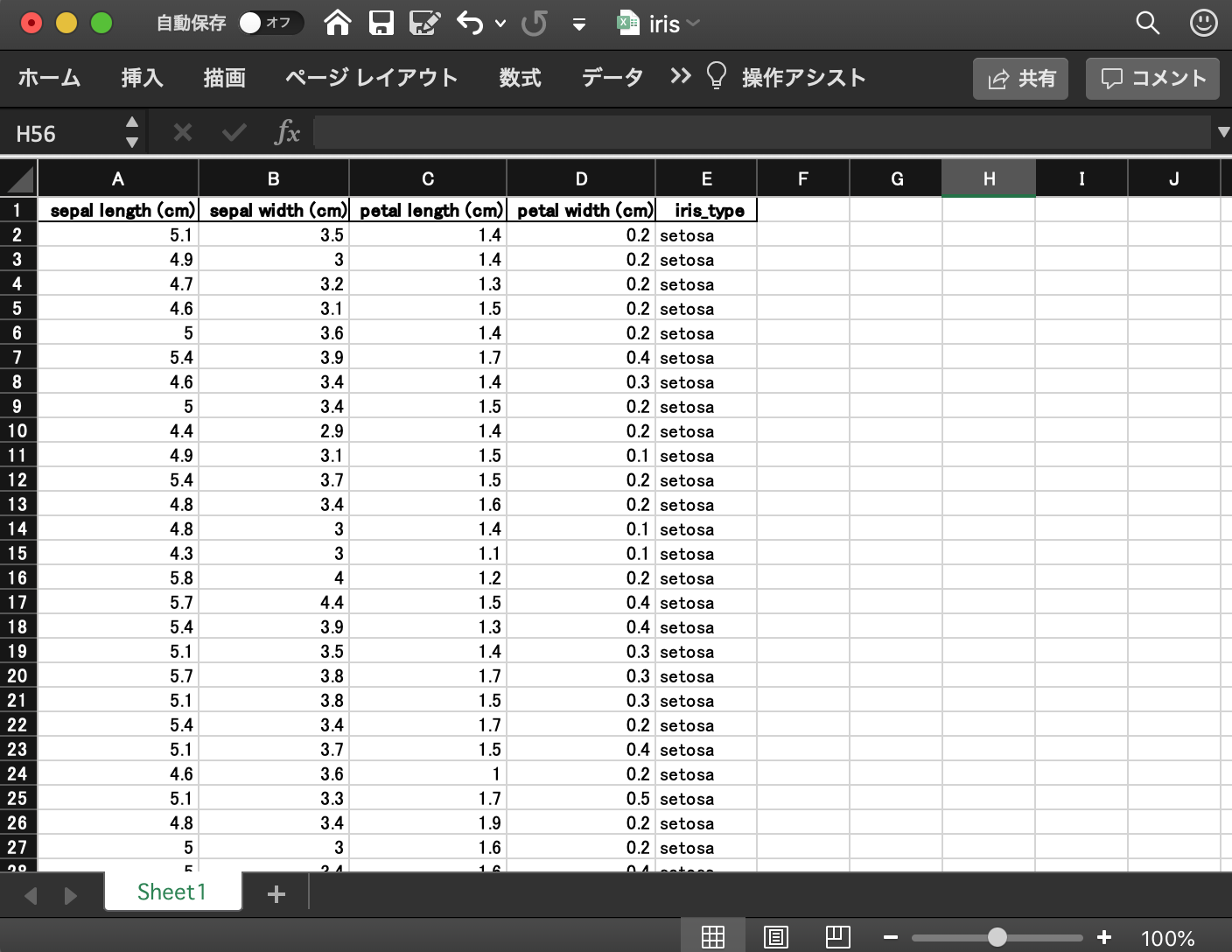 You have successfully saved 150 lines of Iris data in Excel format.
You have successfully saved 150 lines of Iris data in Excel format.
Recommended Posts