[PYTHON] real-time-Personal-estimation (learning using GPU locally)
at first
Last time I wrote an article with the title of making a new model and verified it, but it turned out to be a disastrous result that I mistaken Nogizaka's Matsun for Yoda-chan. So I knew that the model wasn't working, but I can't give up here. I'm determined to recreate the model and write this article. It was difficult to prepare a learning environment using GPU.
About the environment
OS:windows10 GPU:GTX960 Yolov5
About environment construction
I started by recreating the environment to run Yolo while running the GPU. (1) Introduction of cuda It is necessary to install cuda before installing PyTorch described in (2). Regarding the introduction of cuda There are various sites, but I think it can be done because it is not so difficult. I probably introduced cuda 10.1. The URL is shown below. https://developer.nvidia.com/cuda-10.1-download-archive-base?target_os=Windows&target_arch=x86_64&target_version=10&target_type=exelocal (2) Introduction of PyTorch Introduce PyTorch for cuda 10.1.
pip install torch==1.6.0+cu101 torchvision==0.7.0+cu101 -f https://download.pytorch.org/whl/torch_stable.html
(3) Introduction of Yolov5
Please check that as it is written in the above.
https://qiita.com/asmg07/items/e3be94a3e0f0195c383b
(4) Test learning
I'm writing this article and turning epochs 50 times, but since it doesn't use CPU, the article is very nice.
This part shows only the command used for the time being, and verifies it after learning. </ S>
python train.py --img 640 --epochs 50 --data data.yaml --cfg ./models/yolov5m.yaml --batch-size 2
I finished learning while writing the article.
(5) Verification
 Here is the resulting image. Well, I'm still not sure.
It ended unexpectedly early, so I would like to try epochs 100 times.
Results of 100 times
Here is the resulting image. Well, I'm still not sure.
It ended unexpectedly early, so I would like to try epochs 100 times.
Results of 100 times
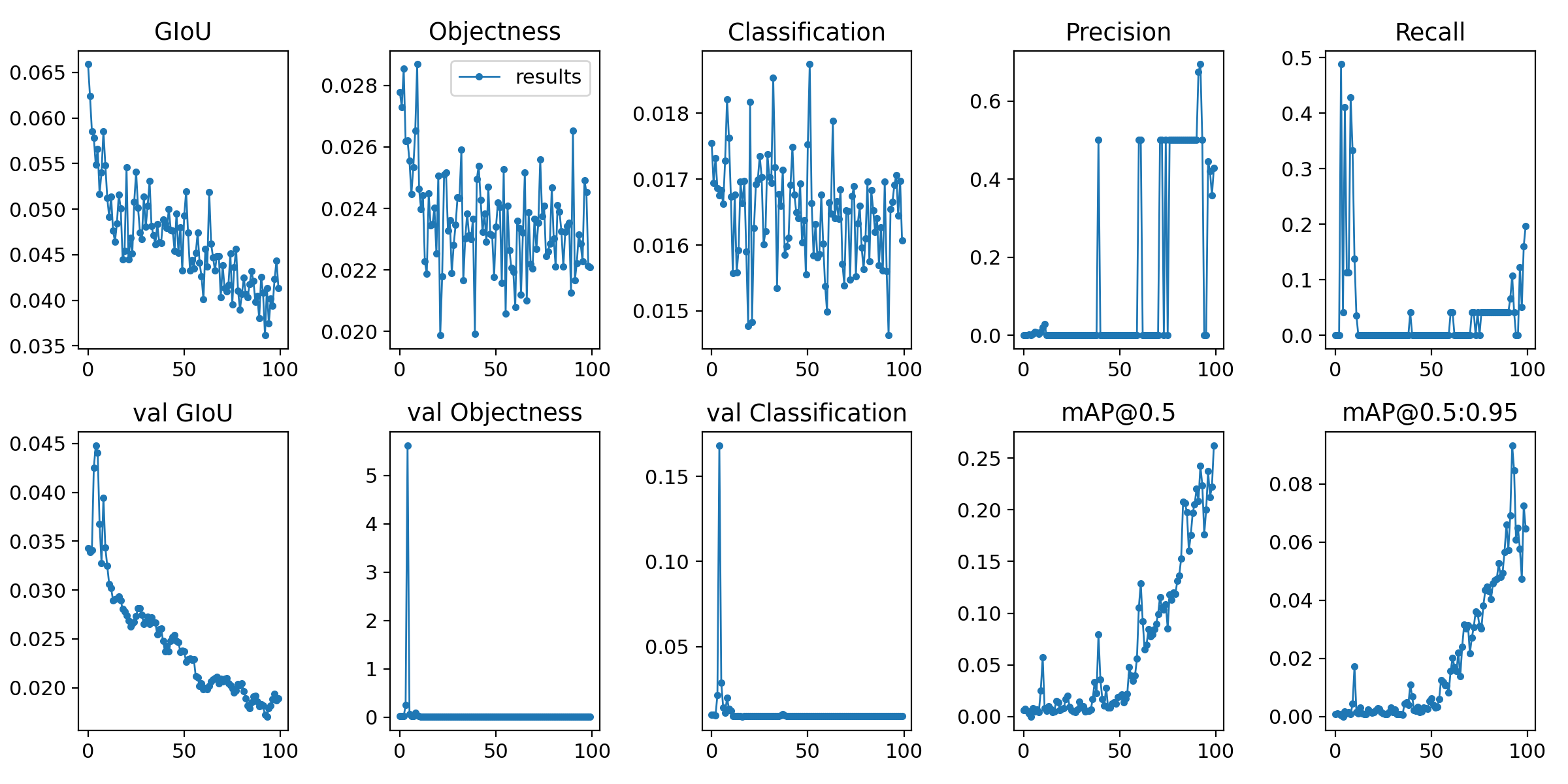
(6) Explanation of learning commands
I'm not sure yet, but I'll explain.
--epochs 50 ➡ times
--batch-size 2
This is important --- why batch-size 2 does this
I am using GTX960 and have 2GB of memory.
If you use a number larger than this, the memory will be larger than this and you will get an error.
So I'm doing it with this. I wonder if there is a dedicated memory and a shared memory in the memory and only the dedicated memory can be used.
Please let me know if there is a way to use shared memory as well.
Finally
I changed the environment for the time being, so I wrote a new article again.
If there is any development, I will write it again.
PS.
I want a comment.
・ Shared memory and dedicated memory.
・ How to avoid inferring within 2 categories when hitting a third image that has not been trained at all when doing it in 2 categories.
I wonder if it is difficult for an individual face with an image that has not been learned
When I did something similar in the past, I put in a third variety of face data that had nothing to do with it and trained it in 3 categories, but I don't want to do that.
I would be happy if you could tell me about this area.
Postscript
⓵ It seems that shared memory cannot be used. ⓶ I trained with epochs 1000.
python train.py --epochs 1000 --data data.yaml --cfg ./models/yolov5s.yaml --batch-size 1
About 80 image data in 2 categories
Output data after training
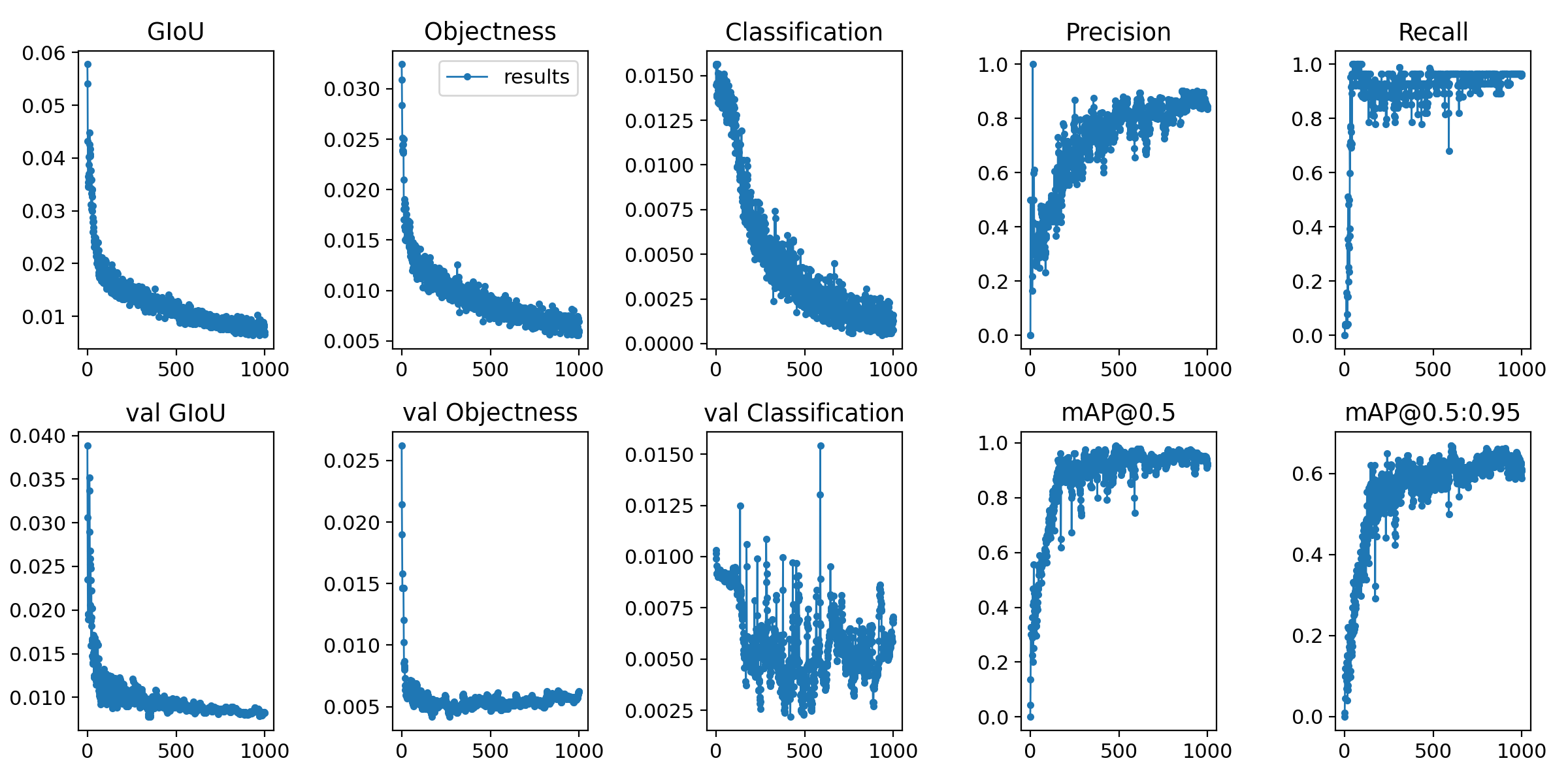 I wondered if this was a pretty good feeling.
・ Results of actual testing with about 100 sheets of data
Out of category (not included in category)
I wondered if this was a pretty good feeling.
・ Results of actual testing with about 100 sheets of data
Out of category (not included in category)


 In category
In category

 Nogizaka-chan's estimation included in the category is working well, but Nogizaka-chan outside the category (not included in the category)
Estimate is not working.
problem
-What to do with the problem of recognizing images outside the category (not included in the category).
In the first place, it is a theory, but after all it may be one of the problems that there is too little learning data.
Nogizaka-chan's estimation included in the category is working well, but Nogizaka-chan outside the category (not included in the category)
Estimate is not working.
problem
-What to do with the problem of recognizing images outside the category (not included in the category).
In the first place, it is a theory, but after all it may be one of the problems that there is too little learning data.
- Please let me know if there is any solution.
Problems that occurred while preparing the environment (question on github)
https://github.com/ultralytics/yolov5/issues/1094 https://github.com/ultralytics/yolov5/issues/1093
Recommended Posts