[PYTHON] Heppoko develops web service in a week # 2 Domain search
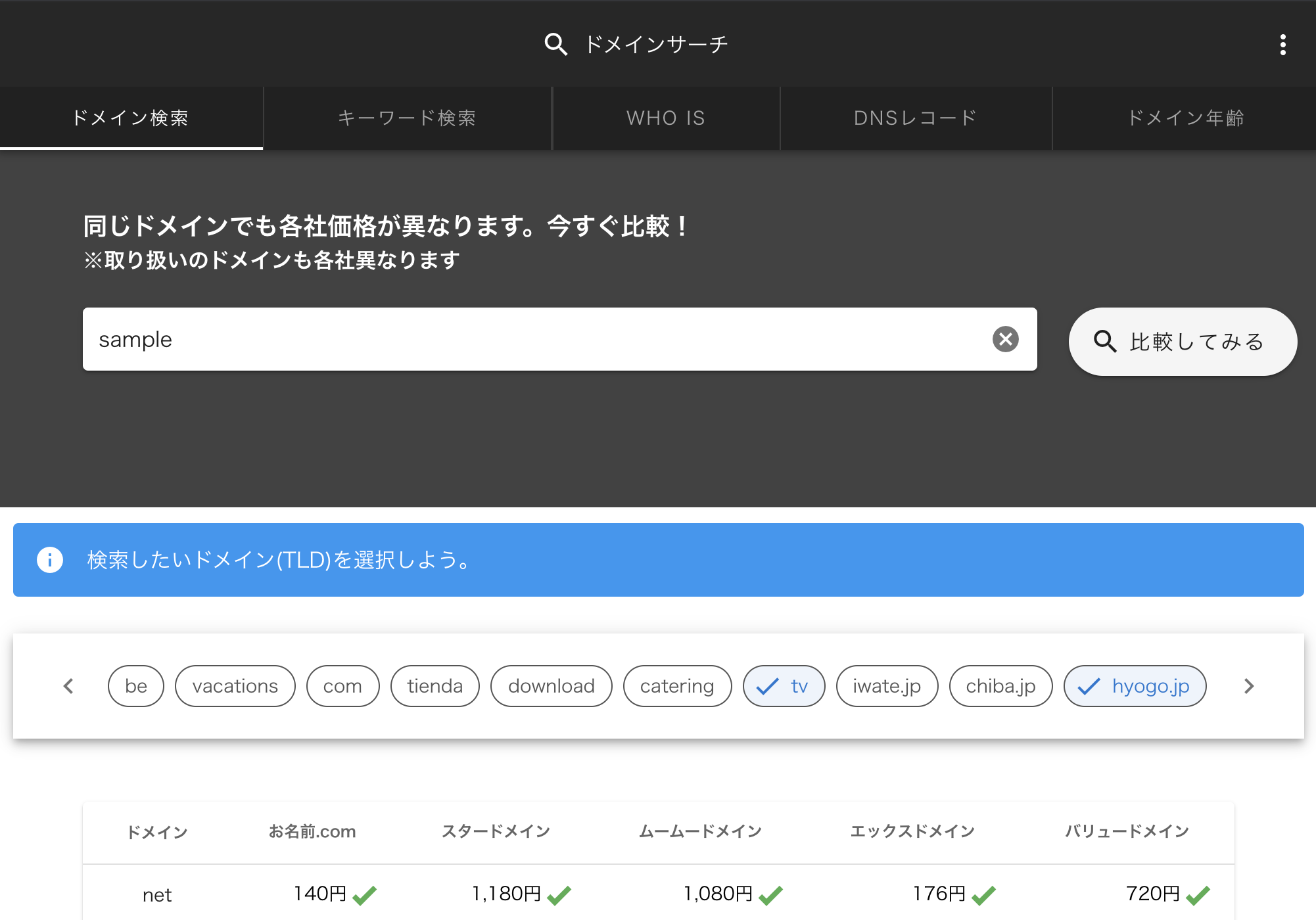
Domain search
Domain search is a service that provides the following functions. Domain Search
- tld search: You can search for the availability and price of the target tld.
- Keyword search: You can search the ranking by any keyword for the target domain.
- WHOIS Search: You can search for the WHOIS domain of the target domain.
- DNS record search: You can search the DNS record of the target domain.
- Domain age: You can search the operating period of the target domain.
My specs
・ Heppoko engineer ・ Development history: 3 years ・ Personal development history: 10th month (I decided to do personal development this year in 2020.01!) ・ Development language: python ・ I finally tried using vue in this development! !! ・ I'm interested in no coding.
Development history
This time as well as last time, it was developed on Dara's web 1week.
I was studying a Vue course at Udemy just before it started, so I'll try Vue right away! That's why I developed it with Vue CLI.
Somehow, NuxtJs had seen somewhere in the mainstream article of Vue development now (an article that starts with Nuxt), but this is the first time, so I developed it quietly with Vue CLI!
Like vue itself, Vue CLI is amazing! I tought.
Technology used
- Language: Vue
- Framework: Vue CLI
- Design: Vutify (I thought this was amazing!)
- Deployment environment: netlify (I thought this was also amazing! Amazing!)
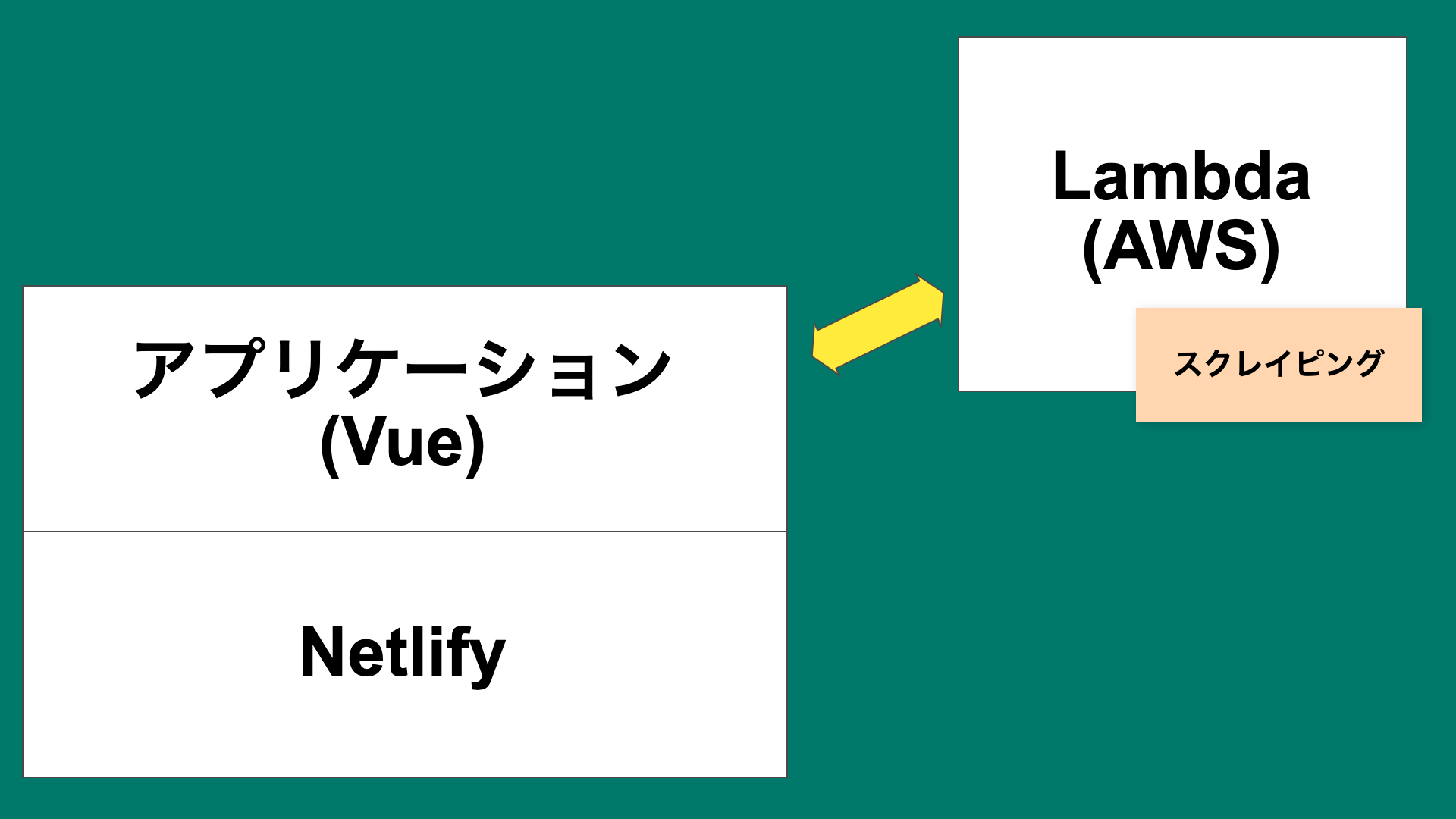
- Backend: lambda (AWS)
Especially great this time! Convenient! It was fun because I was able to develop while thinking! !!
Also, this time I'm scraping with python to get the domain price etc. of each site on the back end.
I put that backend processing in lambda. I used AWS lambda for the first time this time, but this is also amazing! I tought!
Production environment
 This time I used Netlify for the first time.
It is a service that you can set up a custom domain for free.
This time I used Netlify for the first time.
It is a service that you can set up a custom domain for free.
Lambda I also used Lambda for the first time this time. It was a very compatible service for serverless applications.
Initially I was trying to use Google's Cloud Functions with a similar service, but I gave up because the reference to chromedriver described later did not work.
Lambda used python, but in order to refer to the python module in Lambda, it is necessary to upload the target module file to a place called a layer.
Module upload to layer
This time, I will describe how to upload a selenium module to a layer.
mkdir python #First, create the root folder python.
cd python
pip install selenium -t #Download selenium module to current directory
cd ../
zip -r selenium.zip ./* #Finally zip the whole python folder
By uploading the zip file created above to the layer, selenium can be referenced from Lambda and can be read by import.
Not only module files but also python files such as drivers can be referenced in the same way, but if you use lambda, I think it is smarter to place other files in S3 and refer to them.
I myself put the chromedriver needed for scraping this time on S3 and refer to it.
Other
Dynamically change the title and description
This time, I am using VueCLI and unintentionally became a SPA (single page application). .. I used VueRouter to create a pseudo-multi-page structure, but how do I change the title, etc.? .. I stumbled on that.
By referring to the following site, you can change the title etc. wonderfully and dynamically! !! Reference page
Recommended Posts