[PYTHON] Ich war erfreut zu glauben, dass ich in der Lage war, ein Holy Cup-Programm zu erstellen, das mit tiefem Lernen eine Genauigkeit der Vorhersage der FX-Rate (Dollar-Yen) von 88% erreichen würde, aber als ich es mit Produktionsdaten vorhersagte, war es ein Händchen für die Wiederholung von "Ich weiß nicht".
Über diesen Artikel
Es tut mir leid für den Titel des Artikels wie Narurou. "Machen Sie mit Deep Learning (CNN) ein Dollar-Yen-Vorhersageprogramm und werden Sie Millionär!" Aus Begeisterung ist es eine Geschichte, die fehlgeschlagen ist __. __ Beziehen Sie sich andererseits nur auf diejenigen, die Lehrer werden möchten __.
Beschreibung des Liefergegenstandes
Ich möchte nicht zu viel erklären, aber ich werde die Ergebnisse erklären.
Erfahren Sie, wie Sie mit CNN (Convolution Neural Network) Raten mit einer großen Anzahl von Diagrammbildern vorhersagen können.
Ich habe ein Programm erstellt, das nach 24 Stunden drei Optionen ausgibt: "Auf", "Ab" und "Weiß nicht".
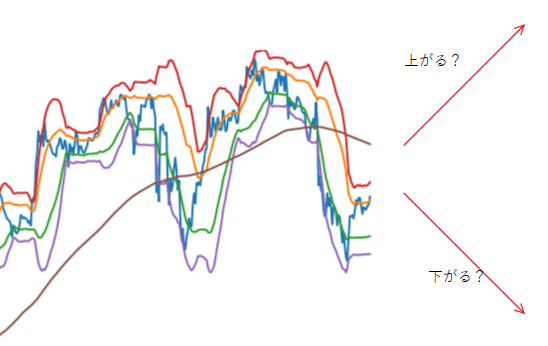 Das Inferenzergebnis war ein gutes Ergebnis mit einer korrekten Antwortrate von 88%.
Wenn Sie es jedoch mit tatsächlichen Daten vorhersagen, wird es viele "Ich weiß nicht" geben. ..
Die Erstellung hat 3 Tage gedauert, daher bin ich mir nicht sicher, wie es gemacht wird.
Ich habe viel aus dem Prozess der Erstellung gelernt, daher werde ich es als Ausgabe belassen.
Das Inferenzergebnis war ein gutes Ergebnis mit einer korrekten Antwortrate von 88%.
Wenn Sie es jedoch mit tatsächlichen Daten vorhersagen, wird es viele "Ich weiß nicht" geben. ..
Die Erstellung hat 3 Tage gedauert, daher bin ich mir nicht sicher, wie es gemacht wird.
Ich habe viel aus dem Prozess der Erstellung gelernt, daher werde ich es als Ausgabe belassen.
Bauumgebung
Erbaut auf Google Colaboratory. Python 3.6 Tensorflow 1.13.1
Datenvorverarbeitung
Aufbereitung von Bilddaten
CNN ist ein tiefes Lernen der Bildklassifizierung.
Sie müssen also viele Diagrammbilder vorbereiten.
Wir haben ungefähr 80.000 Bilddaten wie unten vorbereitet.
 Obwohl die Erstellung von 80.000 Bildern ungefähr 8 Stunden dauerte, habe ich aus dem später beschriebenen Grund tatsächlich 30.000 verwendet.
Informationen zum Erstellen eines Diagrammbilds finden Sie in diesem Artikel .
Obwohl die Erstellung von 80.000 Bildern ungefähr 8 Stunden dauerte, habe ich aus dem später beschriebenen Grund tatsächlich 30.000 verwendet.
Informationen zum Erstellen eines Diagrammbilds finden Sie in diesem Artikel .
Anordnung von Bilddaten und Speicherung im Binärformat
Lernarbeit kann nicht mit Bilddaten durchgeführt werden, wie sie sind. Ich muss die Bilddaten in ein Numpy-Array konvertieren und habe sie alle 10.000 Blatt im Npy-Format gespeichert.
import glob
import cv2
import numpy as np
X=[]
#Listen Sie die Zielbilder auf
img_list = glob.glob('<Zielordner zum Speichern von Bildern>/*.png')
#Bildgröße anpassen
for i in range(len(file_list)):
file_name = '../Make_img/USDJPY/' + str(i) + '.png'
img = cv2.imread(file_name)
img = cv2.resize(img, dsize=(150, 150)) #Größe ändern
X.append(img) #Zur Liste hinzufügen
#Speichern Sie alle 10.000 Blätter im Binärformat
if (i > 0) and (i % 10000 == 0):
#In numpy konvertieren und als binär speichern
X = np.array(X)
npy_name = 'traintest_' + str(i) + '.npy'
np.save(npy_name, X)
X = []
Dann gibt es 0,7 GB npy-Dateien pro Datei,
Mit 80.000 Blatt ist die Kapazität auf fast 6 GB angewachsen.
Diesmal werden die auf Google Drive gespeicherten Daten Ich habe vor, es mit Google Colob zu laden und daran zu arbeiten. Es ist nicht gut, eine so große Datei hochzuladen. Komprimieren Sie mehrere npy-Dateien zu einer und kombinieren Sie sie im npz-Format.
- Ich werde später feststellen, dass es nicht notwendig war, das Array in npy zu konvertieren und von Anfang an zu speichern.
arr1 = np.load('traintest_10000.npy')
arr2 = np.load('traintest_20000.npy')
arr3 = np.load('traintest_30000.npy')
arr4 = np.load('traintest_40000.npy')
arr5 = np.load('traintest_50000.npy')
arr6 = np.load('traintest_60000.npy')
arr7 = np.load('traintest_70000.npy')
arr8 = np.load('traintest_80000.npy')
np.savez_compressed('traintest_all.npz', arr1 , arr2, arr3, arr4, arr5, arr6, arr7, arr8)
Beim Komprimieren wurden es ungefähr 0,7 GB.

Anfangs habe ich die Größe auf 250 * 250 geändert. Durch das Laden mit Google Colab stürzte der Speicher ab und ich änderte die Größe auf 150 * 150. Bei dieser Größe sind einige Teile unscharf, und ich mache mir Sorgen, ob ich die Funktionsmenge gut erfassen kann. Dies kann einer der Gründe sein, warum diese Vorhersage fehlgeschlagen ist.
Lesen Sie mit Google Colab Trainingsdaten, Testdaten und korrekte Antwortetiketten
Laden Sie die erstellte npz-Datei auf Google Drive und hoch Starten Sie GoogleColab und laden Sie es.
#Paketimport
from tensorflow.keras.callbacks import LearningRateScheduler
from tensorflow.keras.layers import Activation, Add, BatchNormalization, Conv2D, Dense, GlobalAveragePooling2D, Input
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import SGD
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.regularizers import l2
from tensorflow.keras.utils import to_categorical
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
%matplotlib inline
#Google Drive-Mount
from google.colab import drive
drive.mount('/content/drive')
#Lesen Sie den npz, der die Quelle des Datensatzes ist
loadnpz = np.load(r'/content/drive/My Drive/traintest_all.npz')
Stellen Sie sicher, dass 8 Elemente richtig gelesen wurden.

Trennen Sie als Nächstes die Bilder für die Schulung und Überprüfung. Lesen Sie jeweils 10.000 Blatt.
- Wenn Sie mehr als dies lesen, stürzt der Speicher beim Lernen ab.
#Trainings- und Testbilddatensatz
train_images = loadnpz['arr_0']
test_images = loadnpz['arr_1']
Nach dem Lesen der CSV-Datei mit dem richtigen Antwortetikett mit DataFrame wird sie in ein Array konvertiert. Trennen Sie nach der Konvertierung die richtigen Antwortetiketten für Schulung und Überprüfung.
#Satz korrekter Etiketten
df = pd.read_csv(r'/content/drive/My Drive/Colab Notebooks/npy Datei/tarintest_labels.csv')
df['target'] = df['target'].replace('Up', '0')
df['target'] = df['target'].replace('Down', '1')
df['target'] = df['target'].replace('Flat', '2')
df['target'] = df['target'].astype('int')
labels_arr = df['target'].to_numpy() #Beschriftungsteil in Array konvertieren
#Etikettendaten trennen
train_labels = labels_arr[0:10001] #Für das Training
test_labels = labels_arr[10001:20001] #Zur Überprüfung
Etikettendaten werden in das OneHot-Format konvertiert.
#In das OneHot-Format konvertieren
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
Wenn Sie dies tun können, überprüfen wir die Anzahl der Formen.

Modellieren
Als nächstes wird das Modell erstellt. Dieses Mal werden wir es mit einer Struktur namens ResNet erstellen. Wenn Sie sich fragen, was ResNet ist, lesen Sie bitte diesen Artikel .
Wenn die zu lesenden Bilddaten zu groß sind, stürzt der Speicher wiederholt ab und wird überhaupt nicht fortgesetzt. In diesem Fall ist es erforderlich, die batch_size während des Trainings oder die Bilddaten selbst zu reduzieren. In meinem Fall habe ich anfangs 250 * 250 Bilddaten verwendet und konnte aufgrund einer Reihe von Speicherabstürzen nicht alle fortfahren. Daher habe ich die Größe auf 150 * 150 geändert.
#Erzeugung einer Faltungsschicht
def conv(filters, kernel_size, strides=1):
return Conv2D(filters, kernel_size, strides=strides, padding='same', use_bias=False,
kernel_initializer='he_normal', kernel_regularizer=l2(0.0001))
#Erzeugung des Restblocks A.
def first_residual_unit(filters, strides):
def f(x):
# →BN→ReLU
x = BatchNormalization()(x)
b = Activation('relu')(x)
#Faltschicht → BN → ReLU
x = conv(filters // 4, 1, strides)(b)
x = BatchNormalization()(x)
x = Activation('relu')(x)
#Faltschicht → BN → ReLU
x = conv(filters // 4, 3)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
#Faltschicht →
x = conv(filters, 1)(x)
#Passen Sie die Formgröße der Verknüpfung an
sc = conv(filters, 1, strides)(b)
# Add
return Add()([x, sc])
return f
#Erzeugung des Restblocks B.
def residual_unit(filters):
def f(x):
sc = x
# →BN→ReLU
x = BatchNormalization()(x)
x = Activation('relu')(x)
#Faltschicht → BN → ReLU
x = conv(filters // 4, 1)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
#Faltschicht → BN → ReLU
x = conv(filters // 4, 3)(x)
x = BatchNormalization()(x)
x = Activation('relu')(x)
#Faltschicht →
x = conv(filters, 1)(x)
# Add
return Add()([x, sc])
return f
#Erzeugung von Restblock A und Restblock B x 17
def residual_block(filters, strides, unit_size):
def f(x):
x = first_residual_unit(filters, strides)(x)
for i in range(unit_size-1):
x = residual_unit(filters)(x)
return x
return f
#Form der Eingabedaten
input = Input(shape=(150,150, 3))
#Faltschicht
x = conv(16, 3)(input)
#Restblock x 54
x = residual_block(64, 1, 18)(x)
x = residual_block(128, 2, 18)(x)
x = residual_block(256, 2, 18)(x)
# →BN→ReLU
x = BatchNormalization()(x)
x = Activation('relu')(x)
#Pooling-Schicht
x = GlobalAveragePooling2D()(x)
#Vollständig verbundene Schicht
output = Dense(3, activation='softmax', kernel_regularizer=l2(0.0001))(x)
#Modell erstellen
model = Model(inputs=input, outputs=output)
#Umstellung auf TPU-Modell
import tensorflow as tf
import os
tpu_model = tf.contrib.tpu.keras_to_tpu_model(
model,
strategy=tf.contrib.tpu.TPUDistributionStrategy(
tf.contrib.cluster_resolver.TPUClusterResolver(tpu='grpc://' + os.environ['COLAB_TPU_ADDR'])
)
)
#kompilieren
tpu_model.compile(loss='categorical_crossentropy', optimizer=SGD(momentum=0.9), metrics=['acc'])
#ImageDataGenerator-Vorbereitung
train_gen = ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True)
test_gen = ImageDataGenerator(
featurewise_center=True,
featurewise_std_normalization=True)
#Berechnen Sie die Statistiken für den gesamten Datensatz vor
for data in (train_gen, test_gen):
data.fit(train_images)
Lernen
Lernarbeit durchführen. Obwohl ich es auf das TPU-Modell umgestellt habe, dauert es aufgrund der Kapazität fast 5 Stunden.
#Vorbereitung für LearningRateScheduler
def step_decay(epoch):
x = 0.1
if epoch >= 80: x = 0.01
if epoch >= 120: x = 0.001
return x
lr_decay = LearningRateScheduler(step_decay)
#Lernen
batch_size = 32
history = tpu_model.fit_generator(
train_gen.flow(train_images, train_labels, batch_size=batch_size),
epochs=100,
steps_per_epoch=train_images.shape[0] // batch_size,
validation_data=test_gen.flow(test_images, test_labels, batch_size=batch_size),
validation_steps=test_images.shape[0] // batch_size,
callbacks=[lr_decay])
Nach dem Lernen beträgt die korrekte Antwortrate (val_acc) in den Verifizierungsdaten 88%!
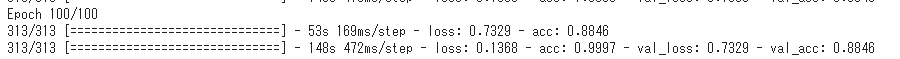
Vorhersage mit realen Daten
Laden Sie neue Verifizierungsdaten in test_images und versuchen Sie, eine Vorhersage zu treffen.
test_predictions = new_model.predict_generator(
test_gen.flow(test_images[0:10000], shuffle = False, batch_size=16),
steps=16)
test_predictions = np.argmax(test_predictions, axis=1)[0:10000]
Das Vorhersageergebnis wird mit drei Auswahlmöglichkeiten ausgegeben: "0: Aufwärts", "1: Abwärts" und "2: Weiß nicht". Lass uns nachsehen.

"2: Ich weiß nicht" wird wiederholt ... An einigen Stellen gab es "0: hochgehen" und "1: runtergehen", Die richtige Antwortrate war ein katastrophales Ergebnis von weniger als 50% ...
Warum hast du versagt?
Ich denke, die folgenden zwei sind groß.
- Die Bildgröße nach der Größenänderung war zu klein und die Merkmale zu rau.
- Zu wenige Bilder während des Überprüfungszeitraums
1 kann durch Vergrößern des Bildes gelöst werden, Die kostenlose Google Colab-Umgebung ist schwierig. Wenn Sie ein bezahltes Mitglied mit einer monatlichen Gebühr von 10 US-Dollar werden, können Sie anscheinend doppelt so viel Speicher verwenden, sodass dies möglicherweise behoben wird.
2 kann sich bis zu einem gewissen Grad verbessern, da Sie verschiedene Diagrammmuster lernen können, indem Sie alle Bilder mischen. Es kann auch möglich sein, das Bild selbst absichtlich zu vereinfachen und die Anzahl ähnlicher Diagramme zu erhöhen. Das Bollinger-Band wird in dem Artikel verwendet, kann jedoch verbessert werden, indem es entfernt und nur der Schlusskurs und die Linie des gleitenden Durchschnitts aufgezeichnet werden.
Gegenmaßnahme 2 kann kostenlos durchgeführt werden, daher werde ich es in meiner Freizeit versuchen.